Delta Live Tables (DLT) is a product designed by Databricks to help with ETL development. It is built on top of Apache Spark, helping it to provide a consistent and efficient environment for your data to be processed.
Let’s take a look at some key reasons that Delta Live Tables is growing in popularity.
1. Declarative Pipeline Development
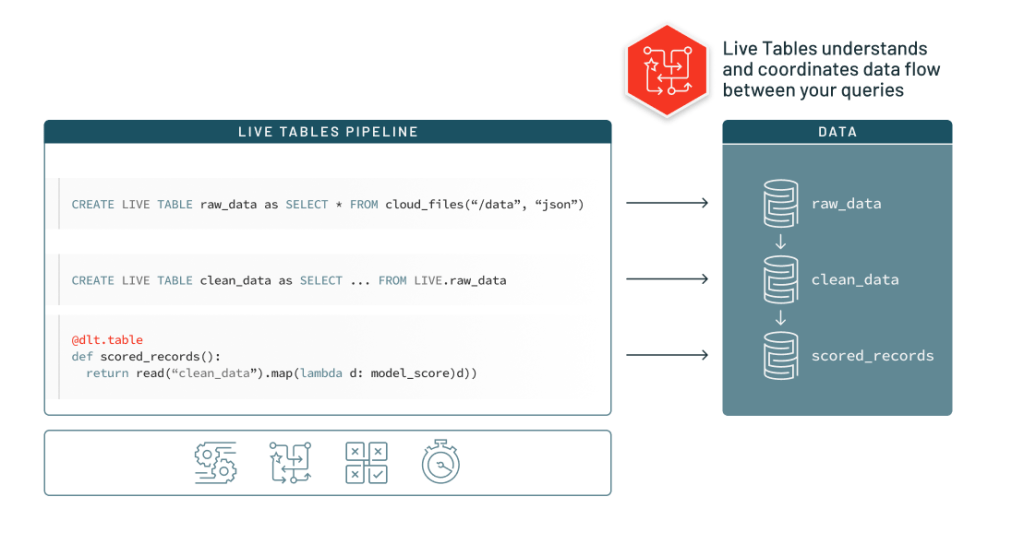
Databricks is very keen to show off what it calls ‘Declarative Pipeline Development’.
In reality, this means that all tables in your pipeline will be declared independently in different cells of code, but also that each can be referred to by name downstream.
For example, if we consider the following table declaration in Python:
@dlt.table(
name="raw_table",
table_properties={"quality": "bronze"}
)
def raw_table():
return spark.read.csv("..../data.csv")We can see that the table raw_table has been declared, very simply, as being the data contained within a CSV file.
Additionally, consider the following code:
@dlt.table(
name="cleansed_table",
table_properties={"quality": "silver"}
)
def cleansed_table():
return dlt.read("raw_table").fillna("N/A")This code defines a table named cleansed_table, which refers to the raw_table table by name. When the pipeline is ultimately built, Delta Live Tables will notice the dependency between the two tables and ensure that raw_table is ran before cleansed_table. This is shown below:
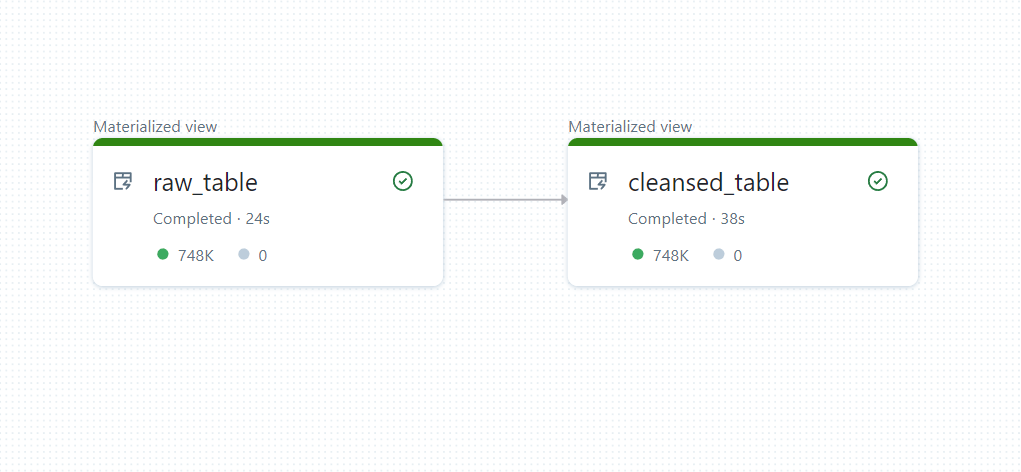
Having these dependencies automatically be created just by declaring tables based on other tables is incredibly powerful and, for me, is one of the main selling points of the product.
2. Multi-language Support

Delta Live Tables (DLT) offers seamless integration with multiple programming languages. This flexibility allows developers and data engineers to leverage their preferred language while harnessing the power of DLT for real-time data processing.
With DLT, you can utilize languages like Python, Scala, Java, and SQL to write code and perform operations on your streaming data. This multi-language support empowers teams to work with DLT using their existing skill sets and programming preferences.
For instance, if you are proficient in Python, you can leverage popular libraries like Pandas and NumPy to manipulate and transform your streaming data using DLT’s Python API. Alternatively, if you are comfortable with Scala or Java, you can take advantage of the rich ecosystem of Spark libraries and APIs to process and analyze real-time data with DLT.
By supporting multiple languages, DLT promotes collaboration among team members with diverse skill sets, allowing them to leverage their expertise in their language of choice. It also facilitates code reuse and accelerates development cycles by providing a familiar environment for developers.
Whether you prefer Python, Scala, Java, or SQL, DLT offers a unified platform for real-time data processing that accommodates your language preferences, making it a versatile tool for teams working with different programming languages.
3. Scalability
Scalability is one of the most fundamental aspects of Delta Live Tables, due to its setup.
DLT leverages Apache Spark’s distributed computing framework, enabling it to distribute the workload across multiple nodes and parallelize data processing tasks. This distributed nature allows DLT to scale horizontally, meaning you can add more computing resources as needed to accommodate growing data volumes or handle spikes in data ingestion rates.
As your data requirements increase, DLT automatically partitions and distributes data across the cluster, ensuring optimal resource utilization and efficient parallel processing. This ability to scale horizontally empowers you to handle diverse workloads, from small streaming data sets to massive data streams with billions of events per day.
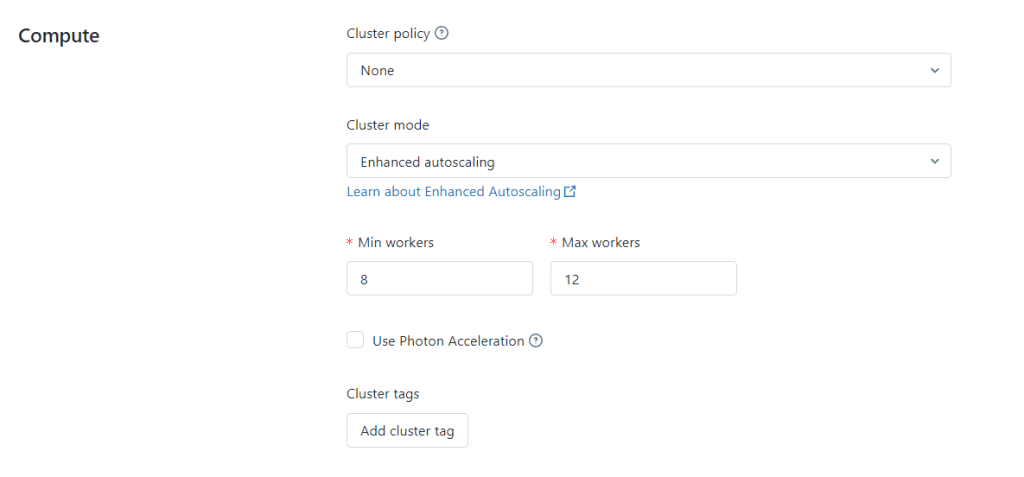
The image above shows this autoscaling in action. In this example, we specify that we want to split the work across a minimum of 8 worker nodes. In the case that the job is particularly large, this can scale up to 12 workers. These are completely customisable, as are the types of worker nodes that can be used.
In short, Delta Live Tables can be as powerful as you like, or as cost-effective as you like, depending on your needs.
4. Integration with Delta Lake and Parquet
ACID transactions form a crucial aspect of reliable and consistent data processing, and DLT seamlessly integrates with Delta Lake to provide robust transactional capabilities. Delta Lake is an open-source storage layer built on top of Apache Parquet and Apache Hadoop Distributed File System (HDFS) that enhances data reliability and ensures ACID compliance.
DLT leverages Delta Lake’s transaction log, which captures every data operation and guarantees atomicity, consistency, isolation, and durability. Let’s explore each component in more detail:
- Atomicity: DLT ensures atomicity by treating a set of data operations as a single unit of work. If any operation in the set fails, all changes made during that unit of work are rolled back, ensuring that the data remains in a consistent state.
- Consistency: DLT enforces consistency by providing schema validation during data writes. It ensures that the written data adheres to the predefined schema, preventing inconsistencies and maintaining data integrity.
- Isolation: DLT provides isolation by allowing concurrent data operations without interference. Delta Lake’s transaction log maintains a versioned view of the data, enabling multiple readers to access consistent snapshots of the data while preserving isolation.
- Durability: DLT guarantees durability by persisting data changes to reliable storage, such as HDFS or cloud-based storage. In the event of system failures or crashes, Delta Lake can recover data to its last consistent state by replaying the transaction log.
Additionally, Delta Lake’s compatibility with DLT enables advanced features like schema evolution, time travel, and metadata management. Schema evolution allows you to evolve the schema of your data over time while ensuring backward compatibility. Time travel lets you query and retrieve historical snapshots of data, enabling auditability and reproducibility. Metadata management simplifies data discovery and governance by storing metadata alongside the data.
The integration of DLT with Delta Lake provides the foundation for building reliable and transactional real-time data workflows. By leveraging Delta Lake’s ACID transaction support and additional features, DLT ensures data integrity, consistency, and durability, making it a robust choice for applications that require reliable and consistent data processing.
5. Working Inside Databricks

By now, most people working in data and analytics (or software development in general) should have heard of Databricks.
Founded in 2013 by the original creators of Apache Spark (which, of course, DLT and Databricks as a whole rely heavily on), Databricks quickly became a very popular tool and is now a comprehensive data engineering and analytics platform.
One of the most key reasons why Delta Live Tables is becoming successful is that it is fully enclosed and supported within Databricks, currently nestled into the Workflows section.
To regular users of Databricks or even those that regularly use other Notebook based IDEs, this will seem very familiar.
In addition, this means including many other benefits of Databricks, such as integration with Git, notebook revision history, collaboration with other users and many more.
All of this should help new users of the tool become very familiar very quickly.
Conclusion
Delta Live Tables is quickly becoming a very prominent tool in the world of Data Engineering and Analytics. I hope that with these 5 points, I have gone some way to showing you why. It’s time to head into DLT yourself – best of luck!

Leave a reply to 3 Reasons Data Cleansing is Critical in Data Analysis – Jammos Analytics Cancel reply